
If you are using Hitachi HAM (High Availability Manager) with HUS VM I would like to ask you to read this.
The post is about an issue/impact we have noticed and that we were able to reproduce in a lab environment.
So I would be interested if you as HAM/HUS VM customer have already noticed this issue, too and – if yes – can provide me feedback (eg. via Twitter @lessi001 or in the comments).
Interested? Here are the details:
Issue description/impacts:
If you are using HDS HAM with HUS VM, there are tasks where you have to do storage path manipulation using a HDS tool called “HGLM” (Hitachi Global Link Manager), eg. to perform a failback after a storage failover or in a planned failover/failback scenario.
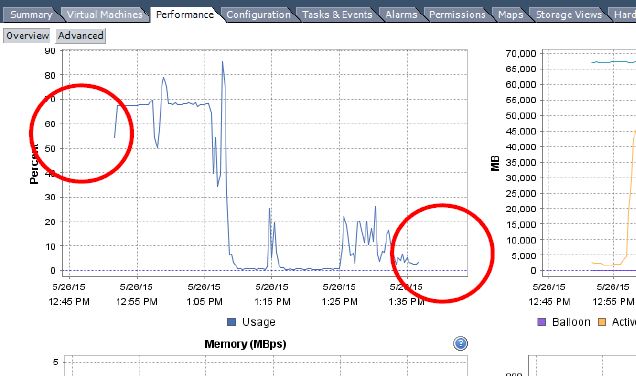
After manipulating a higher number of paths (eg. setting more than 50 paths per host to off or active) we notice the following impacts:
- ESXi host becomes unresponsive
- performance logs are not longer recorded
- up to 100 percent CPU load on ESXi host
These impacts can last from one minute up to three hours – depending on the number of paths, load of the ESXi host and likely the condition of the storage system.
Cause of this behaviour:
HDS HGLM is using the “esxcli storage core path set” command for the path manipulation. Unfortunately, this command triggers a datastore rescan every time when executed.
The rescan is necessary as the command changes the topology of the host storage, and the rescan brings the storage data in hostd/vCenter up to date (info from VMware support/engineering)
So if you manipulate eg. 300 paths, the command triggers 300 storage rescans, too!
And this leads to the impacts as described above, as the hostd cannot deal with this high rate.
In our reproduction scenario we tried the same path manipulation with the “localcli” command. This command does not trigger a rescan in hostd and that’s why the issue is not exposed by “localcli”.
I need your feedback:
If you are a HAM/HUS VM customer and have already noticed these impacts – please get in touch with me (Twitter @lessi001 or via the comments).
If you are a HAM/HUS VM customer and want to know if you have the same issue, you can try to reproduce it in your lab environment. Just catch up with me and I can tell you what we’ve tried.
hi lessi,
we have the exact same issue. wie have aroung 400 paths per host, so it often takes long time till the host becomes responsive again.
haven’t found a solution so far, did you?
cheers
T